
![图片[1]-分享一个自己写的爬取小姐姐python脚本 – MJJ工作室-MJJ工作室](https://image.tiwo.cc/imgs/2020/10/80dfc599298baf93.jpg)
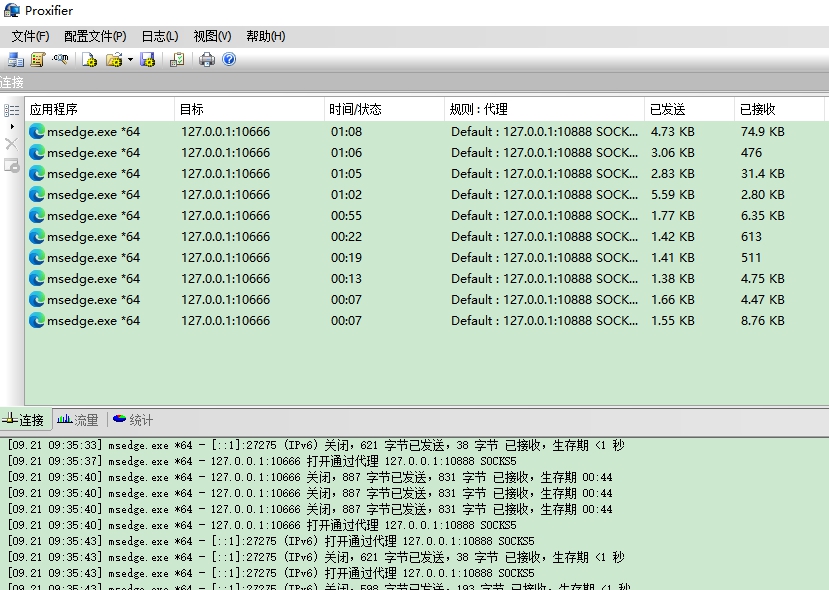
脚本:python3
依赖库:lxml,requests
代码如下:
import requests
import os
from lxml import etree
import threading
import queue
def get_photo(q, download_path):
while True:
try:
url_2 = q.get_nowait() # 不阻塞的读取队列数据,获取图片网址
except Exception as e:
print(e)
break # 若队列为空,则中断循环
try:
photo = requests.get(url_2)
with open(download_path + "/" + "%s" % url_2.split("/",)[-1], "wb") as f:
f.write(photo.content)
except requests.exceptions.InvalidURL:
continue
path = r"/root/photo"
url_0 = r"https://madouplus.com/"
gHeads = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
for i in range(0, 704): # 总共要爬取的页面数
print("正在努力爬取中第%d页....." % i)
if not os.path.exists(path + "/第" + str(i) + "页"): # 爬取内容分页存放
os.makedirs(path + "/第" + str(i) + "页")
path1 = path + "/第" + str(i) + "页"
if i == 0:
url_1 = url_0
else:
url_1 = url_0 + "page/" + str(i + 1) # 获取爬取页面网址
html = requests.get(url_1, headers=gHeads)
xmlContent = etree.HTML(html.content)
hrefList = xmlContent.xpath('//*[@id="posts"]/div/h3/a/@href') # 获得本页美女目录,共计20个
href_1 = xmlContent.xpath('//*[@id="posts"]/div/h3/a/text()') # 获得本页美女目录简介
for i_2 in range(0, len(hrefList)):
# 创建目录
print("正在爬取" + href_1[i_2])
if not os.path.exists(path1 + "/" + href_1[i_2]): # 爬取内容分页存放
os.makedirs(path1 + "/" + href_1[i_2])
download_path = path1 + "/" + href_1[i_2]
url = hrefList[i_2] # 首页第i个美女
html = requests.get(url, headers=gHeads)
xmlContent = etree.HTML(html.text)
PhotoNum = xmlContent.xpath('/html/body/div[2]/div/div[2]/div/article/div[1]/p/img/@src') # 获得首页第i个美女的所有图片网址
photo_text = xmlContent.xpath('/html/body/div[2]/div/div[2]/div/article/div[1]/p[1]/text()') # 获得说明简介
# 不同的标签
if PhotoNum is None:
PhotoNum = xmlContent.xpath('/html/body/div[2]/div/div[2]/div/article/div[1]/div/img/@src')
# 生成说明简介
try:
with open(download_path + '/' + "简介.txt", 'w') as f:
f.write(photo_text[0])
except Exception:
pass
q = queue.Queue()
for url in PhotoNum:
if "http" not in url:
q.put(url_0 + url) # 建立队伍,多进程依次从队伍中获取图片网址
else:
q.put(url)
num = 16
threads = []
for i_1 in range(num):
t = threading.Thread(target=get_photo, args=(q, download_path), name="child_thread_%s" % i_1)
threads.append(t)
for t in threads: # 启动所有子线程
t.start()
for t in threads: # 所有子线程结束,开始继续循环
t.join()
print("任务已完成")
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END




- 最新
- 最热
只看作者